




ChatGPTをはじめとする生成AI(Generative AI)の急速な発展は、研究活動や留学生活に革命的な変化をもたらしています。文献検索、論文要約、プログラミング、英文校正、さらには実験計画のアイデア出しまで、これまで膨大な時間と労力を要したタスクが、AIのサポートによって劇的に効率化されつつあります。
しかし、その圧倒的な利便性の裏には、看過できないリスクも潜んでいます。特に、個人情報や機密性の高い研究データを扱い、高い倫理観と正確性が求められる医学・生命科学分野においては、生成AIの利用に際して細心の注意が必要です。安易な利用は、情報漏洩、研究不正、誤った知見の拡散といった深刻な事態を招きかねません。
本記事では、留学者および医学系研究者の皆様が生成AIを安全かつ効果的に活用するために、特に注意すべき10のポイントと、具体的な対処法を、研究・学習の現場に即した形で詳しく解説していきます。
- 1. 個人情報・患者情報は決して入力しない
- 2. AIの回答は鵜呑みにせず、ファクトチェックを徹底
- 3. 著作権・剽窃リスクを正しく理解し、賢く回避
- 4. 研究の生命線、未公開データ・アイデアは厳重管理
- 5. AIが提案する引用文献リストの落とし穴に注意
- 6. 「AI任せ」にせず、主体的な思考プロセスを大切に
- 7. 利用規約・プライバシーポリシーは「自分事」として確認
- 8. 専門用語・ニュアンスのズレは、プロの目でチェック
- 9. 「AIを使用した」ことを記録・明記する習慣を
- 10. 日進月歩のAIツール、最新情報のキャッチアップを忘れずに
- よくある質問:研究/留学における生成AIとの付き合い方
- まとめ:AIを恐れすぎず積極的に利用しましょう!
1. 個人情報・患者情報は決して入力しない
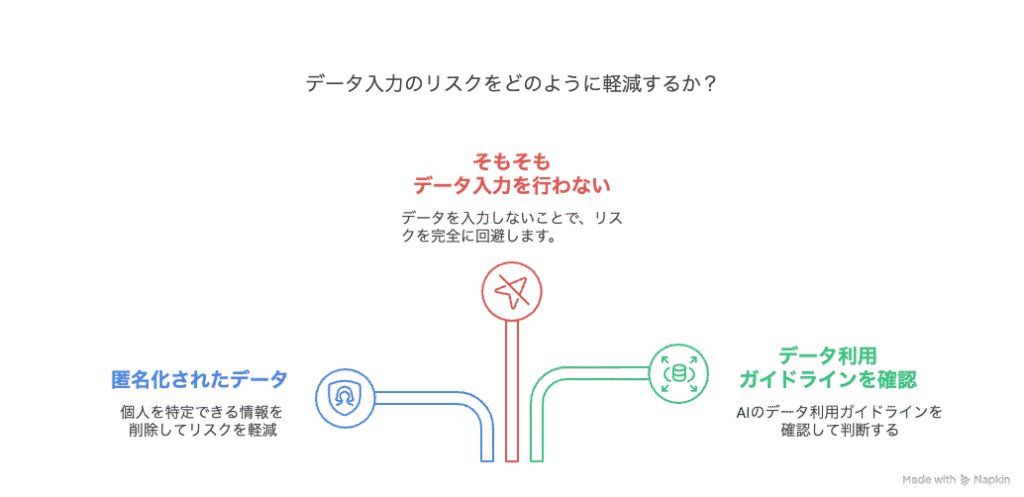
大前提ですが個人情報は入力してはいけません!
リスク: 法規制に抵触し社会問題となるリスク
まず、最も基本的な注意点です。個人情報保護法、GDPR、HIPAAといった国内外の法規制に抵触する可能性があります。患者さんのプライバシーを侵害してしまえば、施設や個人が法的な責任を問われるだけでなく、研究倫理委員会(IRB/REC)の承認内容からも逸脱してしまいます。
対処法: データは匿名化し個人情報は絶対に入力しない
入力するデータは、個人が特定できないように完全に匿名化・仮名化されたものだけにしましょう。氏名、ID、住所、生年月日、連絡先、個人が特定できるほどの詳細な病状記述など、個人を識別できる情報は決して入力しないという意識を徹底することが大切です。
具体例: OKとNGの事例紹介
- ◎ OK: 「60代男性、高血圧の既往歴あり。降圧薬Aを投与中。」といった、誰のことか特定できない臨床サマリー情報。
- × NG: 氏名や患者IDが書かれたカルテ情報のコピー&ペースト。希少疾患の患者さんについて、個人が特定されかねない詳細な状況説明。
- ポイント: 匿名化したデータを使う場合でも、可能であれば所属機関のデータ利用ガイドラインや倫理委員会の規定を改めて確認するのが安全です。
有料契約プランではデータを保存されない選択も可能なAIが多いですが、それをそのまま信じて良いわけではありません。入力しなければリスクはゼロです。
現実的には入力してしまっても第三者にそのままの形で取り出せるわけではないですが、冒さなくて良いリスクは取る必要がありませんね…
2. AIの回答は鵜呑みにせず、ファクトチェックを徹底
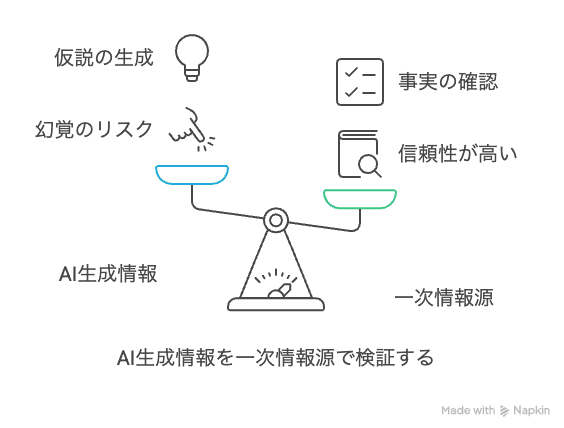
「生成」AIですから、そもそも事実をベースにはしていないんですよね。
リスク: ハルシネーションが含まれる可能性が高い
生成AIは、時に「ハルシネーション(幻覚)」と呼ばれる、もっともらしい嘘の情報を生成することが知られています。これを信じて研究発表や論文に使ってしまったり、臨床判断の根拠にしてしまったりすると、研究自体の信頼性が揺らぎ、ご自身の評価低下にも繋がりかねません。最悪の場合、患者さんに不利益が及ぶ可能性もゼロではありません。
対処法1: 検索AIを使用しつつ必ず一次情報で確認する
AIが生成した情報、特に事実、数値、統計データ、医学的な知見などは、「必ず一次情報源で裏付けを取る」という習慣をつけましょう。PubMedに掲載されている論文、信頼できる学術雑誌、公的機関のガイドラインやデータベース、定評のある教科書などで確認することが不可欠です。AIの回答は、あくまで「仮説」や「議論のたたき台」くらいに捉えておくのが賢明です。
Perplexity.aiやFeloを使用すると具体的な引用元が付くのでハルシネーションのリスクは減りますが、そのページそのものが不正確だったり、要約の過程でニュアンスが変わってしまうこともよくありますのでチェックが不要になるわけではありません。
各AIでは「Deep research」と呼ばれる機能を実装していることがあり、この場合はより確度が高い検索が可能です。しかしその場合でも必ず人の目で事実確認してください。
対処法2: NotebookLMで一次情報を限定してAIを使用
NotebookLMというGoogleが提供している生成AIサービスがあります。このAIの特徴は、読み込ませた情報源からのみ文章の生成や質問への回答を行います。それにより漠然と生成AIに質問を投げかけて創作された内容を表示されたり情報の出所が不明なネットの海からの情報を拾ってしまったりすることを防げます。
論文のBackground作成や研究申請書の作成ではNotebookLMの使用がおすすめです!
具体例: 論文や診療ガイドラインを直接確認する
- AIが「薬剤Xが疾患Yの第一選択薬です」と答えたら、最新の診療ガイドラインや質の高いレビュー論文で本当にそう推奨されているか確認しましょう。
- AIが提示した罹患率や治療効果などの統計データは、引用元とされる論文や公的統計データベースで元の数値を確認しましょう。
- AIにプログラミングコード生成を手伝ってもらった場合も、そのコードが期待通りに動くか、ロジックに間違いはないか、ご自身の目でしっかり検証しましょう。
人が書いた、AI登場以前の論文ですらさまざまな誤りや不正は日常茶飯事でした。情報にファクトチェックが必要なことには変わりはありませんね。
3. 著作権・剽窃リスクを正しく理解し、賢く回避
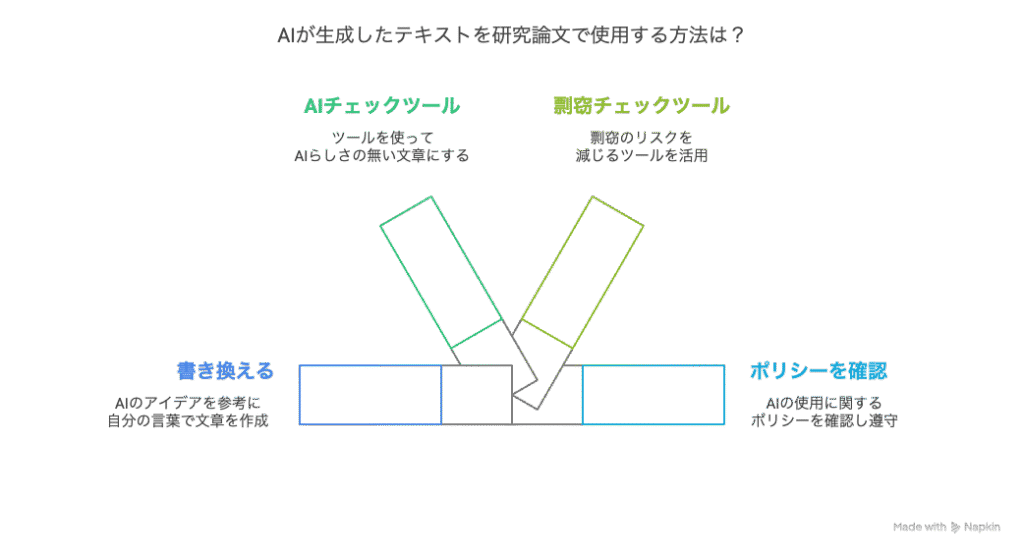
リスク: 著作権侵害で大問題に!?
AIが生成した文章をそのまま自分の論文やレポートにコピペしてしまうと、たとえ悪意がなくても剽窃(盗用)とみなされる可能性があります。これは研究者倫理に反する行為であり、著作権侵害として法的な問題に発展したり、研究者としての信用を失ったり、最悪の場合は学位剥奪などの重い処分につながることもありえます。
対処法1: あくまで下書きに徹する
AIの生成物は、あくまで参考資料やアイデアの種、あるいは下書き程度と考え、最終的な文章は必ずご自身の言葉と考えで文章を作成することを心がけましょう。生成された文章を参考にする場合でも、ダブルクォーテーションマーク(“”)を用いて適切に引用するか、完全に自分の表現に書き換える必要があります。
対処法2: 剽窃チェックツールの使用
心配な場合は、剽窃チェックツール(例:iThenticate, Quillbot)を活用するのも一つの手です。自分で作成した文章でも「たまたま」先行文献と似た文章になってしまうことは多いにあり得ます。理想的には対処法の1と2を併用することが確実と言えるでしょう。
具体例: 一から書き直す・事前にルールを確認する
- AIに論文のIntroductionの草案を作ってもらったら、その構成や参考文献リストは参考にしつつも、文章表現や論理の流れはゼロから自分で書き直しましょう。
- AIが提案した表現が「上手いな」と感じても、そのまま使わずに、文脈に合わせて自分の言葉で言い換えたり、表現を調整したりしましょう。
- 論文を投稿するジャーナルや、所属する大学・研究機関がAI利用に関するポリシーを定めている場合があるので、事前に確認し、ルールを守りましょう。
Quillbotや生成AIにAIらしさをチェックさせることもできます!

4. 研究の生命線、未公開データ・アイデアは厳重管理
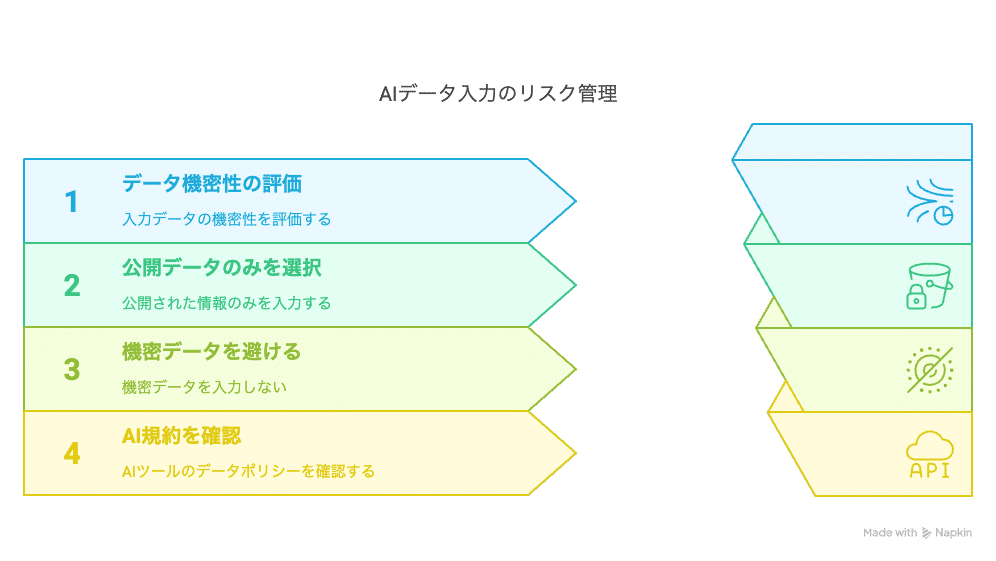
大雑把なアイディアであれ問題ないですが、コアな部分は大事にしましょう!
リスク: データ漏洩で貴重なアイディアが盗まれる!?
多くの生成AIサービス、特に無料版では、ユーザーが入力したデータがAIモデルの学習に使われることがあります。もし、まだ発表していない研究データ、オリジナリティの高い研究計画、実験プロトコル、あるいは研究費申請書の内容などを入力してしまうと、意図せずにその情報が外部に漏れてしまい、研究成果を他者に先取りされたり(スクープ)、貴重なアイデアを盗用されたりするリスクがあります。
対処法: 入力しなければ絶対にバレない
AIに入力するのは、原則としてすでに公開されている情報(発表済み論文、学会抄録、公開データベースの情報など)に限定しましょう。研究室内の機密情報、未発表データ、企業との共同研究で得られた機密情報などは、絶対にAIに入力しないようにしてください。利用するAIツールのデータ取り扱いに関する規約を、面倒でもしっかり確認することが重要です。
具体例: OKとNGポイントはこれ
- ◎ OK: すでに論文として発表した研究結果について、要約文の作成をAIに手伝ってもらう。公開されている実験プロトコルに関して、改善点のアイデアをAIに尋ねてみる。
- × NG: いま進めている実験で得られたばかりの未発表の生データや解析結果を入力して、グラフ作成をAIに依頼する。投稿準備中の論文原稿全文をAIに入力して校正を依頼する(※ただし、契約や設定でデータが学習に使われないことが明確に保証されている場合は例外もありえます)。研究費申請書に書いた、まだ世に出ていない独自性の高い研究計画部分を入力する。
5. AIが提案する引用文献リストの落とし穴に注意
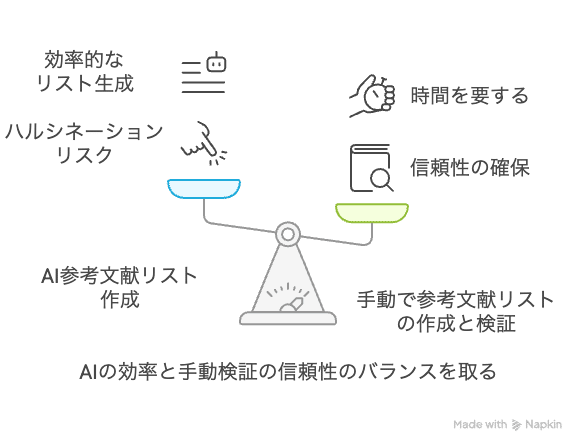
引用文献リスト作成は生成AIの苦手分野です!
リスク: 文献リストにもハルシネーションが混じる
生成AIは、時々、存在しない論文(著者名、タイトル、雑誌名、発行年などがすべて架空)や、研究テーマとは全く関係のない論文を、もっともらしく参考文献リストとして提示することがあります。これは「文献のハルシネーション」と呼ばれ、気づかずに引用してしまうと、研究の信頼性を著しく損なう大きな落とし穴です。
対処法: 文献検索用のAIを使用しつつ自分の目で確認する
AIが提案してきた参考文献リストは、決してそのまま信用せず、必ず一つ一つの文献について、ご自身でその実在と正確性を確認する手間を惜しまないでください。
PubMed、Google Scholar、Scopusといった信頼できる文献データベースを使って、論文タイトル、著者名、雑誌名、巻号、ページ、発行年が正しいか、DOI(Digital Object Identifier)が存在するかなどを、丁寧にチェックしましょう。もちろん、内容がご自身の研究テーマと本当に関連しているかも確認が必要です。
プロンプト(命令文)の工夫でもハルシネーションは減らせますが、あくまで減るだけなので上記のチェックは欠かせません。
そもそもの文献収集についても自由目的で生成AIを使わずにConsensus.aiなどの実際にある文献を検索するためのAIから使うとより確実です。
具体例: Pubmedや文献リストのチェック
- AIに「高血圧と認知症の関連についての近年の主要なレビュー論文をリストアップして」と頼んだ場合、出てきたリストの各論文について、実際にPubMedで検索し、アブストラクトを読んで内容が適切か、そもそも実在するかを確認しましょう。
- AIが生成した文献リストをEndNoteやMendeleyなどの文献管理ソフトに取り込む前に、必ず書誌情報が正確かどうかを目視でチェックしましょう。
2025年以降のAIは検索機能がついてリスクは下がっていますが、内容も含めて引用文献をチェックするのは大前提です!
6. 「AI任せ」にせず、主体的な思考プロセスを大切に
確実なリスクですが対応が難しいものNo.1ですね…
リスク: 思考力が低下する!?
AIがあまりにも便利なので、ついつい頼りたくなりますが、それに慣れすぎてしまうと、自分で深く考える力、物事を多角的に捉える批判的思考力、そして新しいものを生み出す創造性が鈍ってしまうかもしれません。研究活動においては、独自の問いを立て、仮説を練り上げ、論理的に考察を進めるプロセスそのものが非常に重要です。この思考プロセスまでAIに「丸投げ」してしまうと、研究者としての本質的な成長が妨げられる恐れがあります。
対処法: AIの役割を考える
AIを、自分の思考の「代わり」ではなく、思考を深めるための「壁打ち相手」や「発想を広げるツール」として位置づけるのが良いでしょう。まずは自分で問題設定を考え、仮説を立て、大まかな構成案を作るなど、主体的に思考を進めた上で、AIに「別の視点はない?」「このアイデアを補強するデータはある?」といった形で意見を求めたり、アイデアを広げたりする使い方がおすすめです。AIの提案に対しても、「本当にそうだろうか?」と常に批判的な視点で吟味する姿勢を忘れないようにしましょう。
具体例: このような使い方はいかがでしょうか
- 論文のDiscussion(考察)を書く際に、いきなりAIに「考察を書いて」と頼むのではなく、まず自分で主要な結果とその解釈、研究の限界点などを書き出してみます。その上で、「この結果から他に考えられる可能性は?」「この限界点を乗り越えるための次の研究アイデアは?」といった具体的な質問をAIに投げかけ、思考の幅を広げるヒントを得る、といった使い方が効果的です。
- 研究テーマを探す際に、AIにブレインストーミングを手伝ってもらうのは良い方法ですが、最終的にどのテーマを選ぶかは、ご自身の興味関心、指導教員や研究室の方針、利用可能なリソース、実現可能性などを総合的に考えて、主体的に決定しましょう。
一文一文は正しくても前後関係がおかしいことはよくありますので注意です!
7. 利用規約・プライバシーポリシーは「自分事」として確認
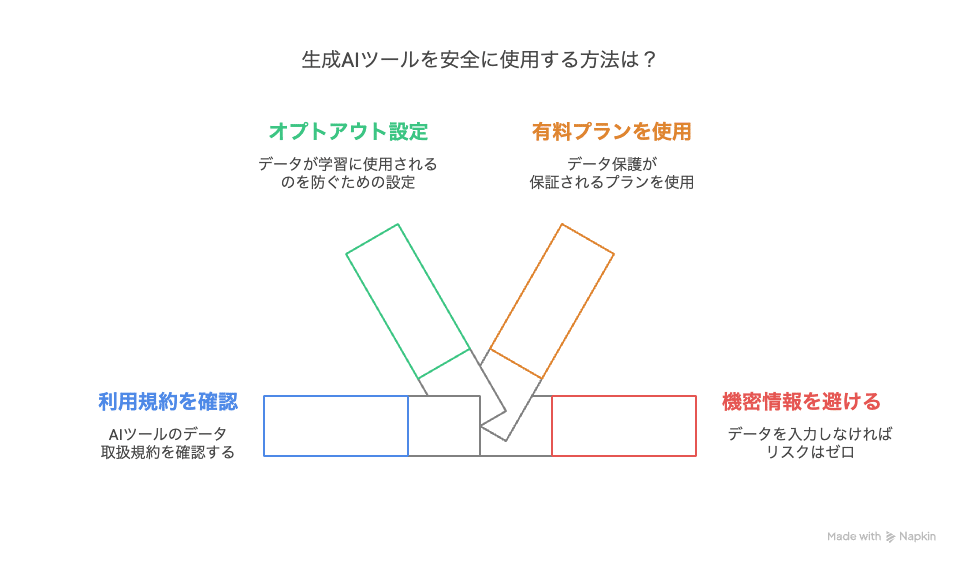
まだまだ生成AIの黎明期なので時々チェックが必要です…
リスク: 知らず知らずに危険を冒しているかも!?
一口に生成AIと言っても、サービスごとに、入力したデータをどう扱うか(学習に使うか、など)、生成されたコンテンツの権利(著作権など)はどうなるか、といったルール(利用規約やプライバシーポリシー)は異なります。これらを読まずに使っていると、知らないうちに自分の入力した情報がAIの学習に使われてしまったり、作ったコンテンツの利用範囲が制限されていたり、といった思わぬ事態になりかねません。
対処法: プライバシーポリシーや利用規約の確認が必要
利用しようと考えているAIツールの利用規約(Terms of Service)とプライバシーポリシーには、必ず事前に目を通しておくことをお勧めします。特に、入力したデータがAIの学習に使われるかどうか(そして、それを拒否できるか=オプトアウトできるか)、生成された文章や画像の著作権は誰に帰属するのか、商用利用は可能か、といった点は、研究や学習で使う上で非常に重要です。もし所属する大学や研究機関が推奨していたり、契約していたりするツールがあれば、そちらを優先的に使うのが安心かもしれません。
具体例: 漏洩のリスクが少ない使い方を
- 無料版のChatGPTは、初期設定では入力データが学習に使われる可能性があるため、もし機密性の高い情報を扱う可能性がある場合は、設定画面で履歴保存と学習利用をオフにする(Opt-out)手続きをするか、データが学習に使われないことが保証されている有料プラン(Team, Enterpriseなど)やAPI経由での利用を検討しましょう。
- 大学や研究機関によっては、特定のAIツール(例えば、Microsoft Azure OpenAI Serviceなど)とデータ保護に関する特別な契約を結んでいる場合があります。情報システム部門などに問い合わせて、利用できるツールやその際の注意点を確認してみると良いでしょう。
個人で使用する場合にはそもそも「機密情報は入力しない」が一番確実で安全です!
8. 専門用語・ニュアンスのズレは、プロの目でチェック
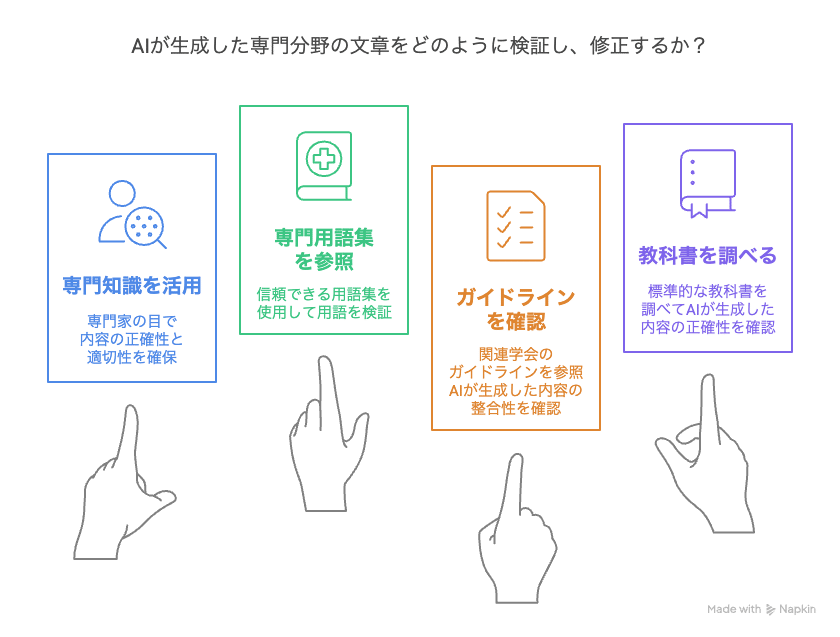
この対策に近道はありませんね…
リスク: 知らず知らず変な言葉遣いでレベルがバレてしまうかも
生成AIは一般的な文章作成能力は非常に高いですが、医学や生命科学のような専門分野特有の、微妙な言葉の使い分けや文脈に応じたニュアンスの理解は、まだ完璧ではありません。用語のわずかな違いが、意味の大きな誤解につながることも少なくないのがこの分野の特徴です。不正確な記述は、研究の質を下げ、読者に誤解を与える原因となります。特に、母国語以外で研究活動を行う留学者にとっては、言語の壁も相まって、より注意が必要なポイントです。
対処法: MeSHなど旧来の方法でのチェックを
AIが生成した専門分野に関する文章については、専門家であるご自身の知識をフル活用し、信頼できる専門用語集(例えば、医学分野ならMeSH – Medical Subject Headingsなど)、関連学会のガイドライン、標準的な教科書などと照らし合わせて、用語の正確性や表現の適切性を厳しくチェックしましょう。AIの出力を鵜呑みにせず、必要に応じて加筆・修正を加えることが求められます。
具体例: 実際のAIとの付き合い方
- AIが “mild cognitive impairment” を単純に「軽い認知症」と訳してきた場合、より正確な医学用語である「軽度認知障害」に修正しましょう。この違いは論文や学会発表においては非常に重要です。
- AIに実験プロトコルの草案作成を手伝ってもらった場合、提案された試薬の濃度や反応時間などが、ご自身の実験系やその分野の標準的な手法と比較して妥当かどうか、経験に基づいて判断しましょう。
- 英語で論文を書く際に、AIが提案してきた表現が、その分野の学術論文で一般的によく使われる自然な言い回しかどうか、少し不安に感じたら、PubMedなどで類例を探して確認してみるのが良いでしょう。
2025年以降のAIでもまだまだ改善余地の大きい部分ですね!
9. 「AIを使用した」ことを記録・明記する習慣を
生成AIの使用は前提になりつつありますので要チェックポイントです!
リスク: 正直に開示しないと大変なことに?
研究を進める上でAIを活用したにも関わらず、その事実を開示しない場合、後になってポリシーに反するとして論文撤回(retraction)となってしまうリスクがあります。将来的には論文投稿や研究費申請の際にAIの利用状況を具体的に明記することが広く求められる流れもあります。
対処法: 記録をつけ、適切に開示
どのAIツールを、研究プロセスのどの段階で、具体的にどのように利用したか(例えば、AIに入力した指示=プロンプト、それに対して得られた主要な出力、そしてその出力に対してご自身がどのように判断し、修正を加えたかなど)を、実験ノートや研究記録にこまめに記録しておく習慣をつけることが必要になるかもしれません。論文や学会発表資料においては、必要に応じて「方法(Methods)」のセクションや「謝辞(Acknowledgments)」などで、AIの利用について正直かつ適切に言及しましょう(投稿先のジャーナルや学会のガイドラインに従ってください)。
具体例: ご参考までに
- 研究ノートに、「[日付]:論文草稿の英文校正のため、ChatGPT-4を使用。プロンプト:『以下のパラグラフを、よりアカデミックな表現に修正してください:[原文]』。AIの提案を参考に、特に以下の点を修正:[修正内容の要約]」といった具体的な記録を残しておくと、後々役立ちます。
- 論文のMethodsセクションに、「データ解析の一部には、GitHub Copilotの支援を受けて生成されたPythonスクリプトを使用した。ただし、全てのコードは手動でレビューし、妥当性を検証した。(Data analysis was performed using Python scripts partially generated with the assistance of GitHub Copilot. All code was manually reviewed and validated.)」のように、利用した事実と検証プロセスを記述する(ジャーナルの指示がある場合)。
やりすぎると時間と労力を消耗しますのでどこまで徹底するか悩ましいところですね…。
10. 日進月歩のAIツール、最新情報のキャッチアップを忘れずに

リスク: いつの間にか変わってしまうことも多々あります
生成AIの技術は、本当に日進月歩で進化しています。昨日できなかったことができるようになったり、機能や性能、利用料金、そして重要なデータポリシーなどが頻繁に変わったりします。古い情報のままツールを使い続けていると、知らないうちにデータが意図しない形で扱われてしまったり、便利な新機能を見逃してしまったり、逆に頼りにしていた機能が突然使えなくなってワークフローが止まってしまったり…といったことが起こりえます。
対処法: チェックするしかないがチェックしすぎは時間の無駄
普段よく利用している主要なAIツールの公式サイト、公式ブログ、リリースノートなどを定期的にチェックして、最新情報を把握するように努めましょう。関連する技術ニュースや、所属する学会・研究コミュニティでのAIに関する議論にもアンテナを張っておくと良いでしょう。情報のアップデートに合わせて、ご自身のAIの使い方や、研究室内でのルールなども、必要に応じて見直していく柔軟性が大切です。
具体例: バランスよく付き合いましょう
- 例えば、ChatGPTのデータプライバシーに関する設定方法が変わったというニュースを見たら、すぐに内容を確認し、ご自身の研究データの保護方針に合わせて設定を見直しましょう。
- 画像生成や特定のデータ解析など、自分の研究に役立ちそうな新しい特化型AIツールが登場したら、その性能や利用条件を試しに調べてみて、良さそうであれば導入を検討してみるのも良いかもしれません。
- 所属する学会や研究機関がAI利用に関する新しいガイドラインを発表したり、更新したりした場合は、その内容をしっかり確認し、遵守するようにしましょう。
これまたどこまで時間をかけるかは悩ましいところです。分野にもよりますね。
よくある質問:研究/留学における生成AIとの付き合い方

- Q生成AIを使って論文の要約を作成する際の注意点は?
- A
生成AIは要約作成に便利ですが、情報の正確性を保証するものではありません。要約内容が原文と一致しているか、重要なポイントが抜け落ちていないかを必ず確認しましょう。また、AIが生成した要約をそのまま使用するのではなく、自分の言葉で再構築することが望ましいです。
- QAIに入力するデータの匿名化とは具体的にどうすれば良いですか?
- A
匿名化とは、個人を特定できる情報を削除または置き換えることです。例えば、氏名やIDを削除し、年齢や性別なども特定されにくい範囲で表現します。具体的には、「60代男性、高血圧の既往あり」といった形で記述し、詳細な病状や治療歴なども特定されにくいように配慮します。
- QAIが提案する引用文献の信頼性を確認する方法は?
- A
AIが提示する引用文献は、実在しないものや不正確な情報を含む場合があります。必ずPubMedやGoogle Scholarなどの信頼できるデータベースで文献の存在を確認し、内容を精査してください。特に、論文の著者、タイトル、掲載誌、発行年などを照合することが重要です。
- Q留学先での研究にAIを活用する際、現地の規制やポリシーを確認する方法は?
- A
留学先の大学や研究機関には、AIの利用に関する独自のポリシーや規制が存在する場合があります。まずは所属機関の研究倫理委員会(IRB)や情報セキュリティ部門に問い合わせ、関連するガイドラインや規定を確認しましょう。また、指導教員や現地の同僚にも相談することをおすすめします。
- QAIを使って英語論文の校正を行う際の注意点は?
- A
AIによる英語校正は便利ですが、専門用語やニュアンスの誤訳が生じることがあります。校正後の文章を自分で再確認し、必要に応じて専門家やネイティブスピーカーにチェックしてもらうことが重要です。また、AIが提案する表現が適切かどうかを判断するために、原文と比較しながら確認しましょう。
- QAIを使った研究支援ツールの選び方は?
- A
研究支援ツールを選ぶ際は、以下の点を考慮しましょう:
- 信頼性: ツールの提供元が信頼できるか。
- セキュリティ: データの取り扱いが適切か。
- 機能性: 必要な機能が備わっているか。
- コスト: 予算に見合っているか。
- サポート体制: 問題発生時の対応が迅速か。
これらを総合的に評価し、自分の研究スタイルやニーズに合ったツールを選択してください。
- QAIを使って作成した資料を学会発表で使用する際の注意点は?
- A
AIが生成した資料を学会発表で使用する場合、以下の点に注意が必要です:
- 出典の明記: AIを使用したことを明記し、生成された内容であることを伝える。
- 内容の確認: 情報の正確性を自分で確認し、必要に応じて修正する。
- 倫理的配慮: 他者の著作権を侵害していないか、倫理的に問題がないかを確認する。
これらを遵守することで、発表内容の信頼性を高めることができます。
- QAIを使って作成した文章が剽窃とみなされないためには?
- A
AIが生成した文章をそのまま使用すると、剽窃とみなされる可能性があります。以下の対策を講じましょう:
- 自分の言葉で再構築: AIの出力を参考にしつつ、自分の言葉で文章を作成する。
- 引用の明記: 必要に応じて、AIを使用したことや参考にした資料を明記する。
- 剽窃チェックツールの活用: iThenticateなどのツールを使って、文章のオリジナリティを確認する。
これらの対策により、剽窃のリスクを軽減できます。
- QAIを使って研究アイデアを整理する際の効果的な方法は?
- A
AIを活用して研究アイデアを整理するには、以下のステップが有効です:
- ブレインストーミング: AIに関連キーワードやテーマを入力し、アイデアを広げる。
- 分類・整理: 生成されたアイデアをカテゴリー別に整理する。
- 優先順位付け: 研究の目的や実現可能性に基づいて、アイデアの優先順位を決定する。
- 具体化: 選定したアイデアを具体的な研究計画に落とし込む。
このプロセスを通じて、AIを効果的に活用できます。
- QAIを使った研究活動の記録をどのように管理すれば良いですか?
- A
AIを活用した研究活動の記録管理には、以下の方法が有効です:
- 使用履歴の記録: AIを使用した日時、目的、生成された内容を記録する。
- データの保存: AIが生成したデータややり取りのログを保存する。
- 定期的なレビュー: 記録を定期的に見直し、研究の進捗やAIの活用状況を評価する。
- 共有と報告: 必要に応じて、指導教員や研究チームと情報を共有し、透明性を保つ。
これにより、AIの活用状況を把握し、研究の質を向上させることができます。
まとめ:AIを恐れすぎず積極的に利用しましょう!

以上、留学者や医学系研究者の皆さんに特に気をつけていただきたい、生成AI利用上の10のポイントと対策を見てきました。一つ一つは基本的なことのように思えるかもしれませんが、AIの利用が日常的になる中で、つい「これくらいなら大丈夫だろう」と見落としてしまいがちな点も含まれていたのではないでしょうか。これらのポイントを意識するかどうかで、AI活用の質と安全性は、きっと大きく変わってくるはずです。
生成AIは、留学者や医学系研究者にとって、研究・学習の進め方を大きく変革する可能性を秘めた強力なツールです。その恩恵を最大限に享受しつつ、思わぬ落とし穴にはまらないためには、本記事でご紹介したような注意点を常に心に留め、「賢く、倫理的に、効率的に」AIと付き合っていく姿勢が何より大切になります。
特に、以下の3つの心構えを大切にしてください。
- データ保護の意識を高く持つこと: 自分や他者の大切な情報を守る意識は、研究者の基本です。
- 批判的な思考を忘れないこと: AIは便利な助手ですが、最終的な判断はあなた自身が行います。
- 透明性と説明責任を果たすこと: どのようにAIを活用したかを記録し、必要に応じて説明できるようにしておきましょう。
生成AIは、決して万能の魔法の杖ではありません。私たち人間の知性をサポートし、時にインスピレーションを与え、面倒な作業を効率化してくれる「アシスタント」です。その能力と限界、そしてリスクを冷静に見極めた上で、主体性を持って活用していくこと。それこそが、変化の激しいこれからの国際社会やアカデミアの世界で、皆さんがさらに活躍していくための鍵となるでしょう。
>> 海外研究留学生活で有用な誰でも簡単に使えるおすすめ研究支援ツール10選
>> 英語ができない医師や研究者が研究留学を実現する方法3選
>> 英語力を補う!研究留学のための英語補助ツール7選+α


コメント